Frontier-Engineering Bench
A large-scale benchmark for evaluating AI agents on generative optimization of real-world engineering tasks.
Navers lab · Einsia AI · 2026
Abstract
Engineering optimization — the systematic, iterative improvement of feasible solutions under domain-specific constraints — is a core challenge that AI has not yet been systematically evaluated on at scale. We introduce Frontier-Eng, a benchmark of 47 real-world engineering tasks spanning five broad categories: computing and quantum information, operations research and decision science, robotics and control, optics and communication systems, and physical sciences and engineering design.
Unlike binary pass/fail benchmarks, Frontier-Eng evaluates generative optimization: agents iteratively propose code edits, receive feedback from frozen domain-specific verifiers, and improve under a fixed interaction budget. Analysis of 500-iteration trajectories reveals a dual power-law structure — improvement frequency decays as 1/t and per-improvement magnitude as 1/k (both R-squared above 0.83) — and under a fixed budget, depth dominates width.
News
Medal Score + v1-lite
A fairer way to report scores. New peer-relative metric: on each task the top-3 best scores in the v1 snapshot become gold/silver/bronze baselines, and a model scores 1.00/0.67/0.33 for reaching each, averaged over the task set (normalized) — rewarding only reaching the frontier, not negligible margins. Reported on both v1 (47 tasks) and v1-lite, a 10-task subset across all five categories chosen for tasks that improve gradually under budget. See the Medal leaderboard .
v2 begins
Next stretch is on. The bar moves up — we're seeking fresh task contributions and new baselines. Submit results or propose a task .
v1 Release
It's live. Forty-seven real engineering tasks across five engineering categories — your launchpad to push frontier models and search to the limit. Open the Leaderboard .
Overview
A generative agent iteratively edits task code under a capped interaction budget; each step is compiled or executed by a frozen, read-only domain verifier (numerical kernels, physics or FEM backends, cryptographic checks, emulators, etc.) that returns objectives and constraint signals. The leaderboard aggregates only verifier outputs across 47 real engineering tasks, with no judge model in the scoring loop.
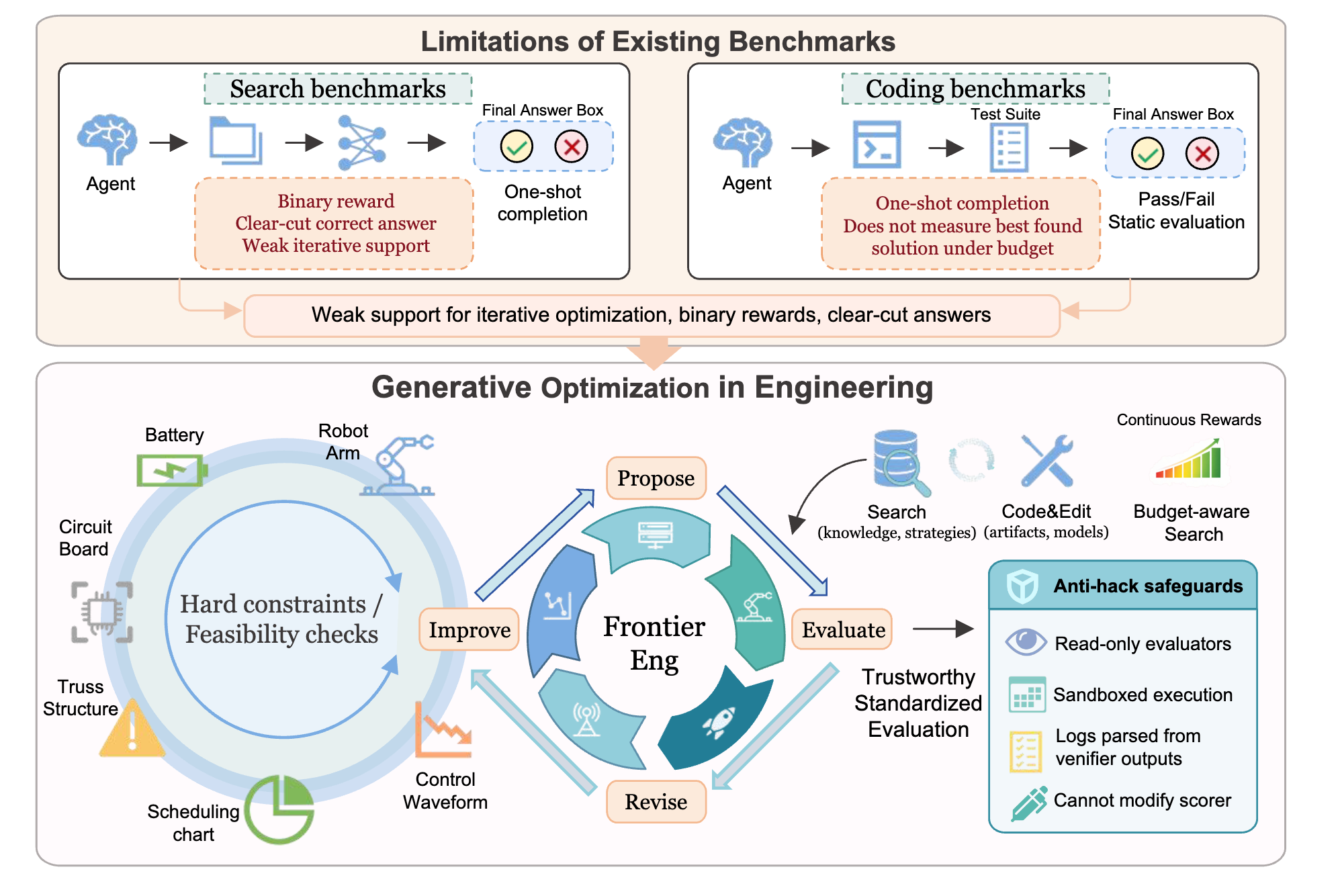
Motivating example
Two tasks show how an agent's running-best score climbs over a fixed budget across search frameworks.


Model leaderboard
Eight frontier models by Medal Score (normalized to [0, 1], higher is better): on each task the top-3 best scores in the v1 snapshot are frozen as gold / silver / bronze baselines, scoring 1.00 / 0.67 / 0.33 for reaching each. Reported on both the full v1 set and the v1-lite subset.
v1 · 47 tasks
| # | Model | Medal | 🥇 | 🥈 | 🥉 |
|---|---|---|---|---|---|
| 1 | GPT-5.4 | 0.596 | 24 | 5 | 2 |
| 2 | Claude Opus 4.6 | 0.490 | 9 | 18 | 6 |
| 3 | GLM-5 | 0.312 | 4 | 10 | 12 |
| 4 | DeepSeek V3.2 | 0.248 | 3 | 9 | 8 |
| 5 | Gemini 3.1 Pro Preview | 0.213 | 3 | 6 | 9 |
| 6 | Seed 2.0 Pro | 0.185 | 3 | 7 | 3 |
| 7 | Grok 4.20 | 0.184 | 3 | 6 | 5 |
| 8 | Qwen3 Coder Next | 0.121 | 3 | 3 | 2 |
v1-lite · 10 tasks
| # | Model | Medal | 🥇 | 🥈 | 🥉 |
|---|---|---|---|---|---|
| 1 | GPT-5.4 | 0.667 | 6 | 1 | 0 |
| 2 | Claude Opus 4.6 | 0.501 | 2 | 4 | 1 |
| 3 | GLM-5 | 0.233 | 0 | 2 | 3 |
| 4 | Gemini 3.1 Pro Preview | 0.200 | 0 | 2 | 2 |
| 5 | DeepSeek V3.2 | 0.166 | 0 | 1 | 3 |
| 6 | Grok 4.20 | 0.133 | 1 | 0 | 1 |
| 7 | Seed 2.0 Pro | 0.100 | 1 | 0 | 0 |
| 8 | Qwen3 Coder Next | 0.000 | 0 | 0 | 0 |
Key findings
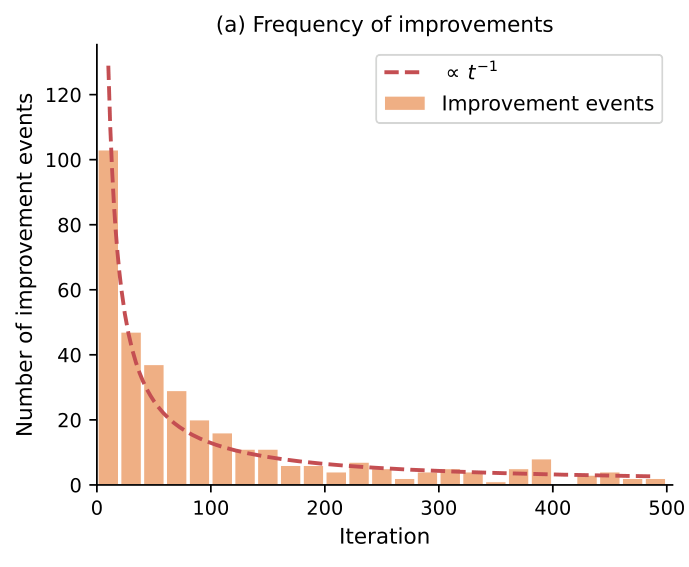
Improvement Frequency Decays as 1/t
Running GPT-OSS-120B on all 47 tasks for 500 iterations, improvement events become rarer following a power law: the majority occur within the first ~30 steps, with a long tail to iteration 500. The 1/t fit achieves R² = 0.84, suggesting a universal diminishing-return structure across engineering domains.
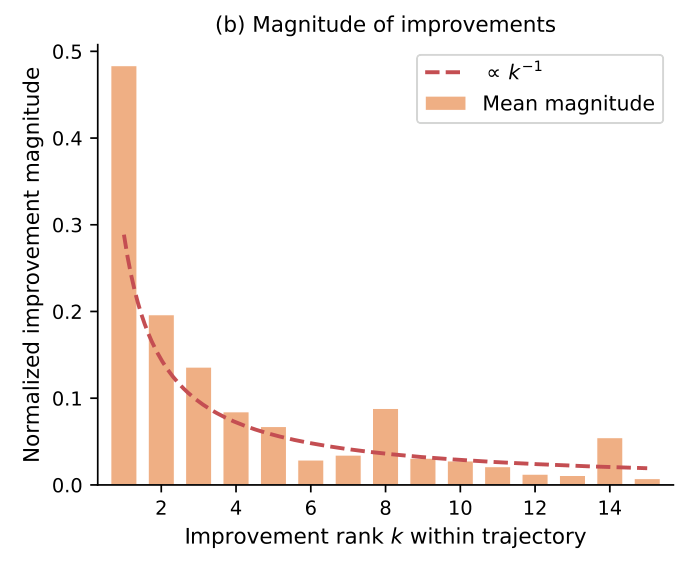
Improvement Magnitude Decays as 1/k
The magnitude of the k-th improvement within each task's trajectory obeys the same power law: the first improvement is a large structural rewrite, while each subsequent one is a smaller incremental refinement. The 1/k fit achieves R² = 0.83, forming a double squeeze that drives marginal returns near zero after ~50–100 iterations.
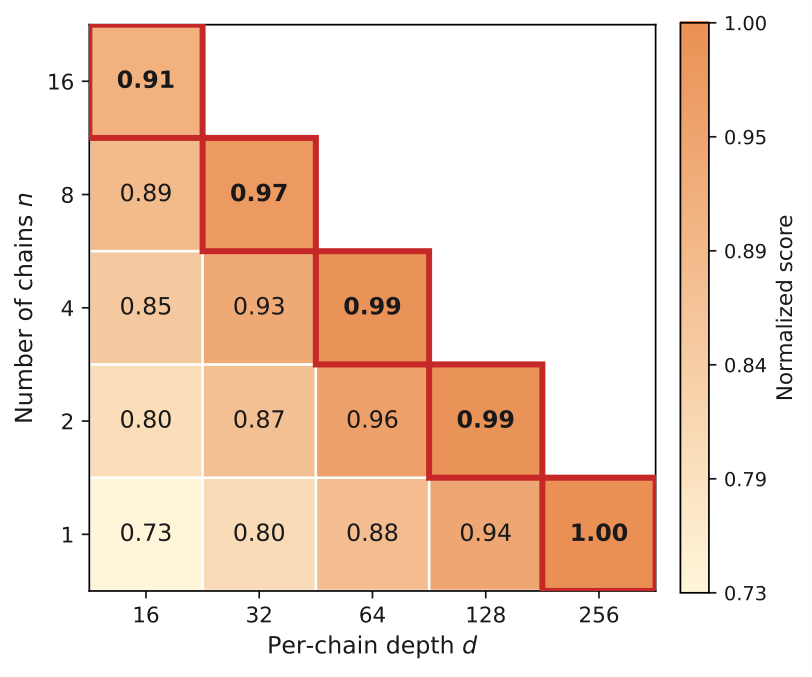
Depth Dominates Width at Fixed Budget
Fixing total budget B = n × d and varying n in {1, 2, 4, 8, 16} on a 10-task subset: along the equal-budget diagonal, the normalized score decreases monotonically with n — 1.00, 0.99, 0.99, 0.97, 0.91 for n = 1 to 16. A single deep chain consistently outperforms spreading budget across restarts.